 |  |



|
#1
 26-02-2011, 11:56 PM
26-02-2011, 11:56 PM
| ||||
| ||||
| 2-3 Trees The 2-3 tree is also a search tree like the binary search tree, but this tree tries to solve the problem of the unbalanced tree. Imagine that you have a binary tree to store your data. The worst possible case for the binary tree is that all of the data is entered in order. Then the tree would look like this: 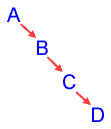 This tree has basically turned into a linked list. This is definitely a problem, for with a tree unbalanced like this, all of the advantages of the binary search tree disappear: searching the tree is slow and cumbersome, and there is much wasted memory because of the empty left child pointers. The 2-3 tree tries to solve this by using a different structure and slightly different adding and removing procedure to help keep the tree more or less balanced. The biggest drawback with the 2-3 tree is that it requires more storage space than the normal binary search tree. The 2-3 tree is called such because the maximum possible number of children each node can have is either 2 or 3. This makes the tree a bit more complex, so I will try to explain as much as possible. One big difference with the 2-3 tree is that each node can have up to two data fields. You can see the three children extending from between the two data fields. 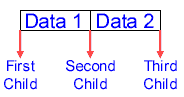 Thus, the tree is set up in the following manner:
class twoThreeTree {You can see that this tree, unlike the binary search tree or the heap tree, has no remove() function. It is possible to program a remove function, but it generally isn't worth the time or the effort. This tree will be a bit harder to implement than the binary search tree just because of the complexity of the node. Still, the add() function algorithm isn't that difficult, and a step-by-step progression through the algorithm helps enormously. First, to add an item, find the place in the tree for it. This is very much the same as in the binary search tree: just compare and move down the correct link until leaf node is reached. Once at the leaf node, there are three basic cases for the add() function:
Using some recursive helper functions as well as that miraculous parent variable will help ease the pain of programming this tree.
__________________    |

 bonfire
bonfire





|
#2
04-12-2011, 11:29 PM
| ||||
| ||||
| Program #include<iostrem.h> #include<conio.h> #define YES 1 #define NO 0 struct leaf { int data; leaf *l; leaf *r; }; class tree { private: leaf *p; public; tree(); ~tree(); void destruct(leaf *p); tree(terr& a); void findparent(int n,int &found,leaf*&parent); void findfordel(int n,int &found,leaf*&parent &x); voide add(int n); voide tranverse(); void in(leaf*q); void pre(leaf*q); voidpost(leaf*q); void del(int n); }; tree::tree() [ p=null; } tree::~tree() { destruct(p); } void tree::destruct(leaf*q) { if(q!=null) { destruct(q->l); del(q->data); destruct(q->r); } } void tree::void findparent(int n,int &found,leaf*&parent); { leaf *q; found=NO; parent=NULL; if(p==NULL) returne; q=p; while(q!=NULL) [ if(q->data==n) { found=YES; returne; } if(q->data>n) { parent=q; q=q->l; } else { parent=q; q=q->r; } } } voidtree::add(int n) { int found; leaf *t,*parent; findparent(n,found,parent); if(found==YES) cout<<"\n such a node exists"; else{ t=new leaf; t->data=n; t->l=NULL; t->=NULL; if(parent==NULL) p=t; else prent->data>n ? parent-> : parent->r=t; } } void tree::tranverse() { int c; cout<<"\n 1.inorder\n 2.preorder\3.postorder\nchoice:"; cin>>c; switch(c) { case 1: int(p); break; case 2: pre(p); break; case 3: post(p); break; } } void tree::in(leaf *q) { if(q!=NULL) { in(q->l); cout<<"\t"<<q->data<<endl; in(q->r); } } void tree::pre(leaf *q) { if(q!=NULL) { cout<<"\t:<<q->data<<endl; pre(q->); pre(q->); } } void tree::post(leaf *q) { if(q!=NULL) {post(q->l); post(q->r); cout<<"\t"<<q->data<<endl; } } void tree::findfordel(int n,int &found,leaf*&parent &x) { leaf *q; found=o; parent=NULL; if(p==NULL) returne; q=p; while(q!=NULL) { if(q->data==n) { found=1; x=q; returne; } if(q->data>n) { parent=q; q=q->l; } else { parent=q; q=q->r; } } } void tree::del(int num) { leaf *parent,*x,*xsucc; int found; //if EMPTY TREE if(p==NULL) { ccout<<"\n tree is epmty"; returne; } parent=x=NULL; findfordel(num,found,parent,x); if(found==0) { cout<<"\nNode to be deleted NOT FOUND"; return; } //if the node to be delete has 2 leaves if(x->l!=NULL && x->!=NULL) { parent=x; xsucc=x->r; while(xsucc->l!=NULL) { parent=xsucc; xsucc=xsucc->l; } x->data=xsucc->data; x=xsucc; } //if the node to be deleted has no child if(x->l==NULL && x->==NULL) { if (parent->r==x ) parent->r==NULL; else parent->l=NULL; delet x; return; { //if node to be has only right leaf if(x->;==NULL && x->!-NULL) { if(parent->l==x) parent->l=x->r; else parent->r=x->r; delet x; return; } //if node to be deleted has only left child if(x->!=NULL && x->r==NULL) { if(parent->l==x) parent->=x->l; else parent->l=x->l; else parent->r=x->l; delet x; return; } } voide main() clrscr() tree t; int data[]=[32,16,34,1,87,13,18,14,19,23,41,5,53} ; for(int i=0;i<15;i++) t.add(add[i]); t.tranverse(); t.del(16); t.tranverse(); t.del(41); t.tranverse(); getch(); }
__________________  SALMAN MUSHTAQ MOB:0333-7465571 Email: mani@bzupages.com Note: For Merit Lists click here ! Merit Lists of BZU Merit List Distance Learning Education 2012 |

 Salman Mushtaq
Salman Mushtaq



 |
| Tags |
| data, structures, trees |
« Previous Thread
|
Next Thread »
| Currently Active Users Viewing This Thread: 1 (0 members and 1 guests) | |
 Linear Mode
Linear Mode

| |

 Similar Threads
Similar Threads | ||||
| Thread | Thread Starter | Forum | Replies | Last Post |
| Concept of Graph in Data Structures. | bonfire | BsTS 2nd Semester | 0 | 26-02-2011 11:55 PM |
| Heap in Data Structures | bonfire | BsTS 2nd Semester | 0 | 26-02-2011 11:52 PM |
| Queue in Data Structures | bonfire | BsTS 2nd Semester | 0 | 26-02-2011 11:51 PM |
| Stacks in Data Structures | bonfire | BsTS 2nd Semester | 0 | 26-02-2011 11:50 PM |
| [PPT] Chapter 2. Data Warehouse and OLAP Technology for Data Mini - Data Mining Concepts and Techniques Han and Kamber | BSIT07-01 | Dataware Housing & data mining | 0 | 03-11-2010 03:10 AM |
Almuslimeen.info | BZU Multan | Dedicated server hosting
Note: All trademarks and copyrights held by respective owners. We will take action against any copyright violation if it is proved to us.
All times are GMT +5. The time now is 02:24 PM.
Powered by vBulletin® Version 3.8.2
Copyright ©2000 - 2026, Jelsoft Enterprises Ltd.
Copyright ©2000 - 2026, Jelsoft Enterprises Ltd.